문제와 정답은 하단에 있습니다!
도움되셨다면 공감♥, 댓글 부탁드려요!
2과목은 16문제 이상 맞춰야 과락을 피할 수 있습니다!
단답형 해설은 여기있습니다!
https://ori-gina-l.tistory.com/14
[SQLD 34회 단답형] 문제공유 + 자세한 해설 (비전공자도 가능)
문제와 정답은 하단에 있습니다! 도움되셨다면 공감♥, 댓글 부탁드려요! 1과목 해설은 여기있습니다! https://ori-gina-l.tistory.com/12 [SQLD 34회 1과목] 문제공유 + 자세한 해설 (비전공자도 가능) 카
ori-gina-l.tistory.com
35회 해설은 여기있습니다!
https://ori-gina-l.tistory.com/18
[SQLD 35회 1과목] 문제공유 + 자세한 해설 (비전공자도 가능) + 문제링크 추가
도움되셨다면 공감♥, 댓글 부탁드려요! 1과목은 4문제 이상 맞춰야 과락을 피할 수 있습니다^^ (틀린 부분은 댓글로 남겨주세요) 35회는 카페에서 완성된 PDF파일이 없고 간단한 문제와 선지정
ori-gina-l.tistory.com
21, 30회 해설은 여기있습니다!
https://ori-gina-l.tistory.com/category/%EC%9E%90%EA%B2%A9%EC%A6%9D/SQLD
'자격증/SQLD' 카테고리의 글 목록
ori-gina-l.tistory.com
11.
DROP : 구조까지 모두 삭제
TRUNCATE : 구조 남으나, 내용이나 인덱스 삭제(용량 줄음)
DELETE : 원하는 데이터만 지우고, 복구 가능, 용량 안줄고 느리다
12
CREATE TABLE SQLD_34_4 (N1 NUMBER, N2 NUMBER ); // (컬럼명 데이터 타입)
INSERT INTO SQLD_34_4 VALUES (1,10);
INSERT INTO SQLD_34_4 VALUES (2,20);
==> 아래 같은 표 생성
| N1 | N2 |
| 1 | 10 |
| 2 | 20 |
1) SELECT N1 FROM SQLD_34_4 ORDER BY N2;
// N1 선택하고, N2로 정렬(선택하지 않은 컬럼으로 정렬가능)
2) SELECT * FROM SQLD_34_4 ORDER BY 2;
// 전체 선택하고, 2번째 컬럼으로 정렬
3) SELECT N1 FROM (SELECT * FROM SQLD_34_4) ORDER BY N2;
// * 이 전체니까 결국 FROM SQLD_34_4랑 같은 말이지
// N1 골라서, N2로 정렬
4) SELECT N1 FROM (SELECT * FROM SQLD_34_4) ORDER BY 2;
// N1 골라서 2번째 열로 정렬? 2번째 열이 없으니까 틀림
13
| Procedure | Trigger | User defined function |
| EXECUTE 명령어로 실행 | 자동 실행(이벤트 발생하면) | |
| CREATE Procedure | CREATE Trigger | |
| COMMIT, ROLLBACK 가능 | COMMIT, ROLLBACK 불가 | |
| DML 많이 쓴다 | ||
| 반드시 값 RETURN 필요X | 반드시 값 RETURN |
14
SELECT CONNECT_BY_ROOT LAST_NAME AS BOSS,
MANAGER_ID,
EMPLOYEE_ID,
LAST_NAME,
LEVEL,
CONNECT_BY_ISLEAF,
SYS_CONNECT_BY_PATH(LAST_NAME,'-') "PATH"
FROM HR.EMPLOYEES
WHERE 1=1
START WITH MANAGER_ID IS NULL
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID
1) PATH를 보면 확인 가능 (-KING만 써있음)
2) CONNECT_BY_LEAF는 최하위 값이면 1, 아니면 0 반환
3) PRIOR 자식 = 부모 면 순방향 (선지 자체가 틀린거)
MANAGER(관리자)가 부모, EMPLOYEE(사원)가 자식
4) LEVEL은 계층의 깊이, KING은 최상위 계층이다 (PATH와 LEVEL 비교하면 확인가능)
15.
SELECT 선수명, 팀명, 연봉 FROM ORDER BY 선수명 ASC, 팀명, 3 DESC
// 선수명 ASC(오름차순) / 팀명(생략, 오름차순이 기본이라 오름차순) / 3 DESC (3번째 열 내림차순)
16.39.
1) HASH 조인(성능향상)이 NL JOIN, SORT MERGE JOIN의 대안
2) 가장 많이 들여쓴 코드부터 실행ㅡ> 2,3 동일 (위에서 부터 실행)
==> 2ㅡ> 3ㅡ> 1ㅡ> 0
3) DEPARTMENT 테이블이 EMPLOYEE보다 소량 선행하는게 좋다
4) 조인조건이 Non-Equal이면 Merge Join (Hash Join X)
| NL Join | Sort Merge Join | Hash Join |
| 랜덤 액세스 | 등가, 비등가 조인 가능 | 등가조인만 가능 |
| 대용량 sort 작업 유리 (sort가 포인트) | 조인키 기준 정렬 | (대량이 포인트) |
| 함수 처리함 | ||
| 선행테이블 작다 | ||
| 별도 저장공간 필요함 | ||
| 인덱스 없으면 유리 |
17.
SELECT SUM(COL1+COL2+COL3+COL4) FROM SQLD_34_08 ; // 4 (NULL은 뭘 더하던 곱하던 NULL)
| COL1 | COL2 | COL3 | COL4 | SUM(COL1+COL2+COL3+COL4) |
| 1 | 1 | 1 | 1 | 4 |
| NULL | 1 | NULL | NULL | NULL |
| 3 | NULL | 3 | 3 | NULL |
| NULL | 4 | NULL | 4 | NULL |
SELECT SUM(COL1) +SUM(COL2) + SUM(COL3) + SUM(COL4) FROM SQLD_34_08 ; = 4+6+4+8 = 22
| COL1 | COL2 | COL3 | COL4 |
| 1 | 1 | 1 | 1 |
| NULL | 1 | NULL | NULL |
| 3 | NULL | 3 | 3 |
| NULL | 4 | NULL | 4 |
| 4 | 6 | 4 | 8 |
SUM(COL1) 은 NULL 무시하고 연산
COUNT(COL1)= 2 (NULL무시하고 행 수 반환 )(마지막 행은 설명하려고 임의로 삽입)
COUNT(*)= 4 (NULL 포함)
18.
1) select coalesce(null,'2') from dual ------------------[2]
// Coalesce는 NULL이 아닌 최초값 반환
2) select nullif('a','a') from dual -----------------------[NULL]
// Nullif(값1, 값2) : 값1 = 값2 ㅡ> NULL 반환
값1 != 값2 ㅡ> 값1 반환 (다르면)
3) select nvl(null,0) + 10 from dual -------------------[10]
// Nvl (값1, 값2) : 값1 isNull ㅡㅡㅡ> 값2
값1 is not Null ㅡ> 값1
4) select nvl(null,'a') from dual -----------------------[a]
19.
| N1 | N2 | C1 | C2 |
| 1 | NULL | A | NULL |
| 2 | 1 | B | A |
| 4 | 2 | D | B |
| 5 | 4 | E | D |
| 3 | 1 | C | A |
순서 : Start with(루트노드 지정)ㅡ> Connect byㅡ> where
1) SELECT C1, C2, N1,N2 FROM SQLD_34_10 WHERE N1=4 START WITH N2 IS NULL CONNECT BY PRIOR N1 = N2 ;
// Start with부터 N2가 NULL 인곳 부터 선택 (1, NULL, A, BNULL) 선택
// Connect by PRIOR N1 = N2 (PRIOR 자식 = 부모) (N1 이전값 = N2 다음값)
N2=4 인 곳까지 모두 선택 가능, N2=1인 마지막행은 N1=1인 행이 상단에 있으니 선택 가능
(사실상 전체가 선택된것)
// Where N1=4 니까 (4, 2, D, B)가 최종선택
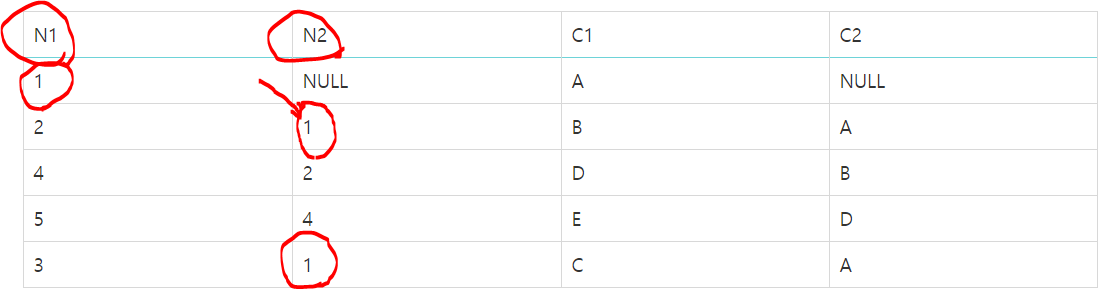
2) SELECT C1, C2, N1,N2 FROM SQLD_34_10 START WITH C2 ='B' CONNECT BY PRIOR N1 = N2 AND C2 <>'D'
// C2=B인곳부터 시작 (4, 2, D, B) 선택
// PRIOR N1= N2 (4, 2, D, B), (5, 4, E, D), 다음 N2=5가 없으니 종료
// C2 <> D 는 C2는 D가 아니다 최종선택 (4, 2, D, B)
3) SELECT C1, C2, N1,N2 FROM SQLD_34_10 START WITH C1 ='B' CONNECT BY PRIOR N1 = N2 AND PRIOR C2 ='B'

// C1=B인곳 부터 시작 (2, 1, B, A) 선택
// PRIOR N1=N2(순방향)으로 내려갈 것,
// PRIOR C2=B (현재 검사하는 행의 이전행의 C2=B인가)
// 현재 검사행 (4, 2, D, B) 전행의 C2는 A라서 선택 불가 최종 선택 (2, 1, B, A)
4) SELECT C1, C2, N1,N2 FROM SQLD_34_10 WHERE C1 <>'B' START WITH N1 =2 CONNECT BY PRIOR N1 = N2 AND PRIOR N1 =2;
// N1=2인 (2, 1, B, A)에서 시작
// PRIOR N1=N2, PRIOR N1=2, (4, 2, D, B) 선택가능 이 다음은 PRIOR N1=2가 아니라 불가 종료
// C1<>B 니까 (2, 1, B, A), (4, 2, D, B) 중 해당하는 거 제거하면 (4, 2, D, B) 선택
20.
SELECT ID, DEPT_NM, SUM(SALARY)
FROM SQLD_34_11
GROUP BY ROLLUP (ID,DEPT_NM); // 롤업은 인수 순서 중요 (ID 총합과 전체 총합 출력)

CUBE는 ID총합, DPET_NM총합, 전체총합 // GroupingSets는 총합없음

21.
SELECT ID, DEPT_NM, SUM(AMT)
FROM SQLD_34_21
GROUP BY ( )
==> ID, DEPT_NM 각각 총합, 전체 총합 출력
==> CUBE(ID, DEPT_NM)
22.
ROLLUP : 인수 순서중요(계층적) / 계층 간 정렬 가능(계층 내 정렬 불가, order by 사용해)
CUBE : 모든값에 다차원집계 생성 / 시스템에 많은 부하
GroupingSets : 인수 순서무관(평등)
23.
SELECT COUNT(*) // 전체선택
FROM SQLD_34_14
HAVING COUNT(*) > 4 // 4 초과인 것 선택
==> 없음 NULL (공집합) (공집합이랑 0은 다른거 알쥬?)
24.
트랜잭션 특성
1. 원자성 : 트랜잭션에서 연산들이 모두 성공 OR 전혀 실행X
2. 일관성 : 트랜잭션 실행 전 DB 내용이 잘못 되지 않으면 실행 후도 잘못 되지 않아야 함
3. 고립성 : 트랜잭션 실행 도중 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다.
4. 지속성 : 트랜잭션이 성공적으로 수행되면 DB의 내용은 영구적으로 저장된다.
25.
SELECT DISINCT COL1 // 중복제거
FROM SQLD_34_16_01 (1, 2, 3, 5, 6) 선택
UNION ALL // 중복 허용 합집합
SELECT COL1 // (1, 2, 2, 4, 5)
FROM SQLD_34_16_02
==> (1, 2, 3, 5, 6) + (1, 2, 2, 4, 5) = 1, 1, 2, 2, 2, 3, 4, 5, 5, 6 (10건)
26.
SELECT COUNT(*)
FROM T1 , T2 , T3 , T4
1) WHERE T1.COL1 = T2.COL1(+) // LEFT OUTER JOIN (왼쪽 꺼 전부 선택, 오른쪽꺼는 왼쪽이랑 겹치는 것만)
2) AND T2.COL1 = T3.COL1(+)
3) AND T3.COL1 = T4.COL1 // INNER JOIN (서로 겹치는 것만 선택)
==> A AND B 는 A와 B 모두 있어야 포함
1) 1, 2, 3, 4
2) 1, 2, 3, NULL
3) 1, 5
=> 1) AND 2) = 1, 2, 3
=> 1)+2) AND 3) = 1
27.
SELECT DEPT_ID, SALARY
FROM (
SELECT ROW_NUMBER() OVER(PARTITION BY DEPT_ID ORDER BY SALARY DESC) RN , DEPT_ID, SALARY
FROM SQLD_34_18 )
WHERE RN = 1
RANK() : 중복값은 중복등수, 등수 건너뜀 (1위, 1위, 3위, 4위)
DENSE_RANK() : 중복값은 중복등수, 등수 안 건너뜀 (1위, 1위, 2위, 2위)
ROW_NUMBER() : 중복값이 있어도 고유 등수 부여 (1위, 2위, 3위, 4위)
PARTITION BY DEPT_ID / ORDER BY SALARY DESC
// DEPT_ID로 그룹묶고, SALARY 많은 순으로 정렬
WHERE RN=1
// 월급 많은 1등 출력
1) RANK() 사용하기 때문에, DEPT_NM=10에서 SALARY=1500으로 1등 2명임
2) SELECT DEPT_ID, MAX(SALARY) AS SALARY
FROM SQLD_34_18
GROUP BY DEPT_ID
(FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY 순으로 실행_
===> 표에서, DEPT_ID끼리 그룹 묶고, MAX(SALARY) 월급 가장 많은 사람과 그 사람 DEPT_ID 선택!
3) ROWNUM=1은 상위 1개 행 가져오는거! (ROW_NUMBER랑 다름!)
4) SELECT DEPT_ID, SALARY
FROM SQLD_34_18
WHERE SALARY = (SELECT MAX(SALARY) FROM SQLD_34_18)
==> 표에서, 전체에서 가장 높은 월급 고름, 그 사람의 ID랑 월급 출력
28.
27번 참조
RATIO_TO_REPORT : 전체 SUM값에 대한 행별 칼럼값, 0~1 사이값
29.
같은 이름의 SAVEPOINT가 저장될 경우 나중에 저장된 SAVEPOINT로 ROLLBACK함
(책갈피라고 생각하면 됨, 오류 발생하면 해당 부분(SAVEPOINT)으로 복원(ROLLBACK))

30.
UPDATE SQLD_34_21 SET N1=3 WHERE N2=1;
CREATE TABLE SQLD_34_21_TEMP (N1 NUMBER);
ROLLBACK;
1) SQL 서버의 경우, AUTO COMMIT 꺼두면 UPDATE, CREATE 모두 취소되고 다시 테이블이 생성되지 않음
2) 오라클은 DDL의 AUTO COMMIT이 기본이기 때문에 CREATE 취소되지않고, UPDATE도 취소X
31.
SELECT 고객ID, 이용일자 // 왼쪽 테이블 전체
FROM SQLD_34_22_01
UNION // 합집합(중복 허용X)
SELECT 고객ID, 이용일자 // 오른쪽 테이블 전체
FROM SQLD_34_22_03 ===> FULL OUTER JOIN
1) A,B 고객ID, 이용일자 중복없이 모두 선택해서 CROSS JOIN

| ID | PRICE | ID | NAME |
| 1 | 100 | 1 | 가 |
| 2 | 200 | 1 | 가 |
| 1 | 100 | 2 | 나 |
| 2 | 200 | 2 | 나 |
2) A,B 고객ID, 이용일자 전부 선택해서 FULL OUTER JOIN
3) A의 고객ID, 이용일자 전부 선택 / 합집합(중복 비허용) / B의 고객ID, 이용일자 전부선택
4) A고객 ID, 이용일자 선택해되, B와 같은 고객ID는 허용X
NOT EXIST(SELECT 'X' // X는 그냥 무시해도 됩니다(존재하냐 마냐 묻는거)
~~
WHERE A.고객ID=B.고객ID)
32.
2) SELECT MIN(ID) FROM SQLD_34_32 GROUP BY NAME
=> FROM 표 선택, 이름으로 그룹 만들고, 가장 작은 ID선택
33.
LIKE
_ : 미지의 한글자
% : 0이상의 글자
(EX _L% : 2번째 글짜가 L인거 모두 다봄) (대소문자 구분!)
ESCAPE : 와일드카드 ( _ % )를 문자로 취급
A(걍 변수) like ‘A_A’
=> a like ‘A@_A’
=> escape ‘@’ (특수문자 아무거나 가능)
35.
1) ROUND : 반올림
2) CEIL : (오라클) 올림
CEILING : (SQL 서버)
36.
CREATE TABLE 주문 (C1 NUMBER, C2 DATE, C3 VARCHAR2(10), C4 NUMBER DEFAULT 100 );
INSERT INTO 주문(C1,C2,C3) VALUES (1, SYSDATE, 'TEST1');
| C1 | C2 | C3 | C4 |
| 1 | GETDATE(SQL서버) |
TEST1 |
1) INSERT INTO 주문 VALUES (2, SYSDATE, 'TEST2')
// 항은 4개인데 값 3개만 INSERT
2,3) DELETE (FROM) 주문 // FROM 생략가능
37.
1) ORDER BY 기본 오름차순 (작은 것부터)
2) SELECT 사용X 것도 ORDER BY 가능 (12번 참조)
3) ORDER BY 1, COL1 혼용 가능
4) 오라클 NULL : ∞
SQL서버 NULL : -∞
38.
SELECT A.회원번호, B.등급
FROM (SELECT 회원번호, SUM(AMT)
FROM SQLD_34_38_01
GROUP BY 회원번호) A , SQLD_34_38_02 B
WHERE 1=1 (그냥 무시해도 ㄱㅊ 무조건 TRUE)
AND A.AMT BETWEEN B.MIN_AMT AND B.MAX_AMT
(순서 : FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY)
=> from절 먼저
=> 회원번호로 그룹 묶고, 회원번호와 그룹끼리 AMT합을 A라고 하고, 2번째 표 전체 선택
=> 거기서 회원번호랑 등급 SELECT
=> AND절 : B의 MIN_AMT ≤ A의 AMT 합 ≤ B의 MAX_AMT
39.
16번 참조
40.
최상위 관리자는 Manager_ID가 NULL이거나 없음
=> 1), 2) INNER JOIN하면 일치하는 것만 가져오니가 최상위관리자 누락
=> LEFT OUTER JOIN, A.MANAGER_ID = B.EMPLOYEE_ID
41.
합집합 : UNION (느림)
중복허용 합집합 : UNION ALL (빠름)
차집합 : MINUS(오라클)
EXCEPT(SQL 서버)
교집합 : INTERSECT
42.
1) Partition by와 Group by는 파티션 분할한다는 점에서 유사
2) 집계 Window Function(sum, max, min) 쓸 때 Window절과 함께하면 레코드범위(집계대상) 지정가능
Window Function은 순위, 합계, 평균, 행위치 조작 가능
Window Function은 행, 행 간 관계 정의하는데 사용
3) Window Function으로 결과 건수 줄지 않음
4) group by, Window Function 병행 불가
단답형 해설은 여기있습니다
https://ori-gina-l.tistory.com/14
[SQLD 34회 단답형] 문제공유 + 자세한 해설 (비전공자도 가능)
문제와 정답은 하단에 있습니다! 도움되셨다면 공감♥, 댓글 부탁드려요! 1과목 해설은 여기있습니다! https://ori-gina-l.tistory.com/12 [SQLD 34회 1과목] 문제공유 + 자세한 해설 (비전공자도 가능) 카
ori-gina-l.tistory.com
출처입니다https://cafe.naver.com/sqlpd/10604
SQLD 34회 기출 바탕 복원 문제 (2019년 8월 시험)
-----------------------------------------------Update : 예정 --------------------------------------...
cafe.naver.com
정답입니다!

'자격증 > SQLD' 카테고리의 다른 글
| [SQLD 30회 단답형] 문제공유 + 자세한 해설 (비전공자도 가능) (2) | 2020.09.01 |
|---|---|
| [SQLD 30회 2과목] 문제공유 + 자세한 해설 (비전공자도 가능) (14) | 2020.09.01 |
| [SQLD 30회 1과목] 문제공유 + 자세한 해설 (비전공자도 가능) (0) | 2020.08.31 |
| [SQLD 34회 단답형] 문제공유 + 자세한 해설 (비전공자도 가능) (3) | 2020.08.31 |
| [SQLD 34회 1과목] 문제공유 + 자세한 해설 (비전공자도 가능) (8) | 2020.08.29 |




댓글